The `preprocessing` package in scikit-learn provides normalization function. Following is how we can do the L1 and L2 norm.
L1 normalization
L1 normalization transforms the data such that the sum of absolute values for each sample (row in a dataframe) is equal to 1.
For example, let’s create small pandas dataframe.
import pandas as pd
from sklearn import preprocessingdf = pd.DataFrame({'A' : [-10,-8,-6,-4,-2, 0],
'B': [0,2,4,6,8,10]
})
df A B
0 -10 0
1 -8 2
2 -6 4
3 -4 6
4 -2 8
5 0 10preprocessing.normalize(df, norm='l1')array([[-1. , 0. ],
[-0.8, 0.2],
[-0.6, 0.4],
[-0.4, 0.6],
[-0.2, 0.8],
[ 0. , 1. ]])We can see above that for each row, the sum of absolute values is equal to 1.
The normalization function returns a NumPy array. However, generally we would want it to be a pandas dataframe with same column names as the original dataframe. This is how we do it.
df_l1 = pd.DataFrame(preprocessing.normalize(df, norm='l1'), columns=df.columns)
df_l1 A B
0 -1.0 0.0
1 -0.8 0.2
2 -0.6 0.4
3 -0.4 0.6
4 -0.2 0.8
5 0.0 1.0L2 normalization
The normalization function does ‘L2’ normalization by default, i.e., when we do not give any value to the norm argument of the normalize function.
It is the Euclidean norm, which transforms data such that the sum of squares of values in each each sample (row in a dataframe) is equal to 1.
We will print out the dataframe first.
df A B
0 -10 0
1 -8 2
2 -6 4
3 -4 6
4 -2 8
5 0 10And, normalize.
We will give the `norm` argument to the function for clarity.
df_l2 = pd.DataFrame(preprocessing.normalize(df, norm='l2'), columns=df.columns)
df_l2 A B
0 -1.000000 0.000000
1 -0.970143 0.242536
2 -0.832050 0.554700
3 -0.554700 0.832050
4 -0.242536 0.970143
5 0.000000 1.000000The normalize function has default `axis` value equal to 1. If the axis=0, then the transformation would act of columns (features) instead of rows (samples)
df_l2 = pd.DataFrame(preprocessing.normalize(df, norm='l2', axis=0), columns=df.columns)
df_l2 A B
0 -0.67420 0.00000
1 -0.53936 0.13484
2 -0.40452 0.26968
3 -0.26968 0.40452
4 -0.13484 0.53936
5 0.00000 0.67420In short, the code for normalization would look like this.
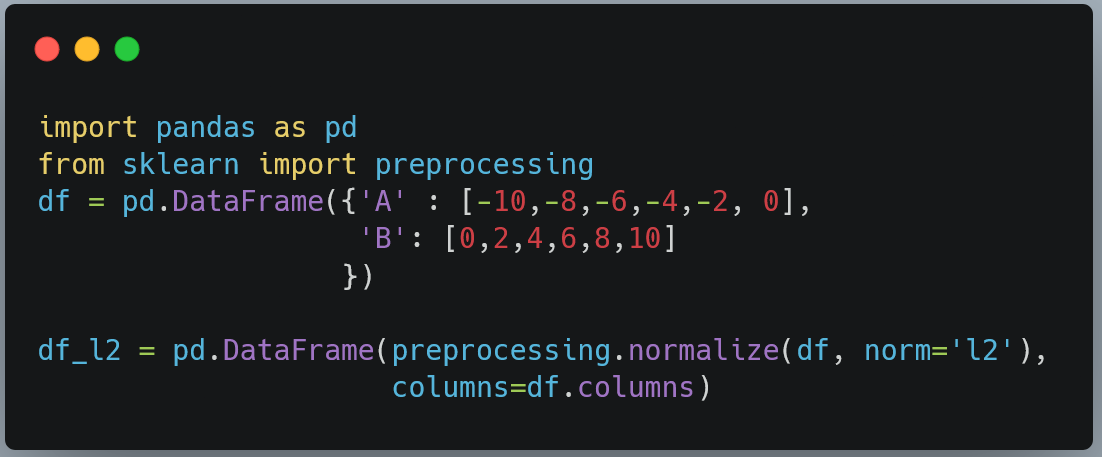
import pandas as pd
from sklearn import preprocessing
df = pd.DataFrame({'A' : [-10,-8,-6,-4,-2, 0],
'B': [0,2,4,6,8,10]
})
df_l2 = pd.DataFrame(preprocessing.normalize(df, norm='l2'),
columns=df.columns)